
Борьба с хардкодами при помощи статических анализаторов С#
В этой статье я расскажу, как мы написали собственные анализаторы кода и чистим с их помощью нашу кодовую базу .net от наиболее острых / частых косяков. Главный посыл — сделать это довольно просто, не бойтесь писать свои анализаторы для борьбы с именно вашими багами. Вторичный посыл — попробуйте наши анализаторы и сообщите о результатах. Полное руководство я писать не буду, их довольно много в интернете, а вот небольшой обзор, что это как и с какими проблемами я столкнулся, надеюсь, окажется вам полезным.
Проблема
В декабре 2016 года я сменил работу и перешел в новую компанию. Новая контора находилась в стадии перехода от «отдел в полтора программиста на коленке лабает небольшой сервис для внутренних нужд» в «ИТ-компания в 100 человек разрабатывает ERP систему для нужд группы компаний и готовит продукт для внешних пользователей».Естественно, в процессе этого перехода многие наколеночные «так принято» вещи становились серьезными и соответствующими разнообразным best practices. В частности, в компании появилась за несколько месяцев до моего прихода полноценная иерархия тестовых сред и отдел тестирования неуклонно боролся за соответствие тестовых сред — среде боевой.
Авторы унаследованной архитектуры исповедовали микросервисный подход, сроки были жесткими, процент джуниоров — большой. Тестеры при развертывании на тестовую среду столкнулись с тем, что внезапно микросервис А, развернутый на тестовой среде, мог вызывать микросервис Б прямо на проде. Смотрим в код — и видим — URL микросервиса Б зашит внутрь кода микросервиса А.
В процессе работы помимо проблемы «захардкоженная ссылка на микросервис» выявились и другие проблемы кода. Code-review check list все рос, ругань становилась все злее. Необходимо было решение, которое выявит все проблемы и предотвратит появление таких ситуаций в будущем.
Статические анализаторы
Новый компилятор языка C# — Roslyn — полностью open source и включает поддержку pluggable static analyzers. Анализаторы могут выдавать ошибки, предупреждения и хинты, работают как во время компиляции, так и в реальном времени в IDE.Анализаторы имеют доступ к AST(абстрактному синтаксическому дереву) и могут подписываться на элементы определенного типа, например на числа или строки или на вызовы методов. В самом простом виде это выглядит как-то так:
private static void AnalyzeLiteral(SyntaxNodeAnalysisContext context)
{
if (syntaxNode is LiteralExpressionSyntax literal)
{
var value = literal.Token.ValueText;
if (value != "@" && value.Contains("@"))
{
context.ReportDiagnostic( Diagnostic.Create(Rule, context.Node.GetLocation(), value));
}
}
(Это моя самая первая попытка написать анализатор для захардкоженных email).
По дереву можно ходить вверх, вниз и вбок, и нет необходимости отличать, скажем, комментарий от строкового литерала — парсер компилятора делает все это за нас. Впрочем, уровня синтаксиса может быть недостаточно. Например,
cs var guid = new Guid("...");
На синтаксическом уровне мы не можем понять, конструктор какого типа мы вызываем. Скорее всего, это System.Guid. А что, если нет? На уровне синтаксического дерева это просто «конструктор класса с идентификатором, равным "Guid"». Для более точной диагностики нам нужно вызвать так называемую семантическую модель и получить у нее информацию о том, какому символу соответствует элемент синтаксического дерева.
private static void AnalyzeCtor(SyntaxNodeAnalysisContext context)
{
if (context.Node.GetContainingClass().IsProbablyMigration())
{
return;
}
if (context.Node is ObjectCreationExpressionSyntax createNode)
{
var type = context.SemanticModel.GetTypeInfo(createNode).Type as INamedTypeSymbol;
var guidType = context.SemanticModel.Compilation.GetTypeByMetadataName(typeof(System.Guid).FullName);
if (Equals(type, guidType))
{
..
}
}
}
Семантическая модель — это промежуточные результаты компиляции. В отличие от синтаксиса, она может быть неполна (напоминаю, мы работаем в контексте IDE, программист может прямо сейчас писать анализируемый класс). Поэтому готовьтесь, методы семантической модели много и часто возвращают null.
Анализаторы ставятся в проект, как обычные NuGet пакеты. После перекомпиляции начинаются проявляться ошибки и предупреждения. Мы в конторе сделали внутренний NuGet пакет (у нас вообще вся сборка всего идет через пакеты), который ставит рекомендованную комбинацию анализаторов. Планируем еще туда дописать наши специфические конторские штуки, и туда же можно добавлять не наши пакеты (я например добавил AsyncFixer, очень удобная штука, всем рекомендую).
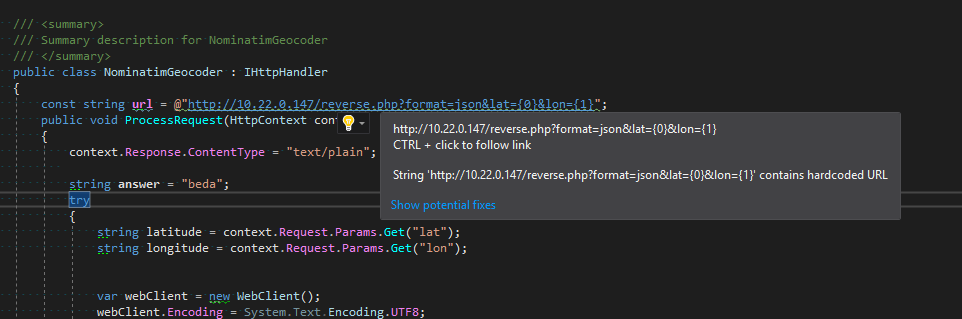
Вот так это выглядит в редакторе
А так в итогах компиляции

Какие анализаторы мы сделали
Анализатор захардкоженных URL
Самый важный для нас анализатор. Тупо ищет все литералы с http, https, ftp и так далее. Список исключений довольно большой — в основном разнообразный автогенеренный код, SOAP атрибуты, namespace и все такое.Анализатор захардкоженной ставки НДС
Редко, но метко встречающаяся в нашем коде проблема. Иногда «сумма с НДС» высчитывается из «суммы без НДС» умножением на 1.18. Это сразу две проблемы. Во-первых, ставка НДС может измениться, и искать все места в коде — большая проблема. Во-вторых, ставка НДС вообще-то — не константа, а атрибут конкретного заказа — он может быть со ставкой НДС 0% (такие юрлица часто бывают у перевозчиков), может относится к другой юрисдикции, наконец, при изменении ставки НДС она изменится для новых заказов, а для старых окажется прежней. Поэтому никакого захардкоженного НДС!В исключения тут попали в основном функции вырезания подстрок (substring). Иногда там имеет смысл передавать жестко прописанное 18. Приходится ловить по именам параметров метода.
Анализатор захардкоженного Guid
Мы часто из кода ссылаемся на id базы (у нас приняты Guid). Это плохо. Особенно мы страдаем из-за таблиц статусов, которым на самом деле стоило бы просто сделать enum (от них мы избавляемся, но они есть). Пока в качестве промежуточного решения мы договорились, что в коде могут встречать id, если они одинаковы во всех средах (значит, создаются миграциями) и если они располагаются непосредственно в коде соответствующей Entity (да, мы используем Entity Framework 6 и не стесняемся).Что у нас в планах
— анализатор захардкоженных email — анализатор, обязывающий писать методы контроллера асинхроннымиВозникшие трудности и странные моменты
Общая библиотека
Естественным было разделить анализаторы по принципу 1 анализатор = 1 assembly = 1 nuget пакет. Дело в том, что все написанные нами анализаторы очень opinionated, и логично предоставить возможность подключать / отключать их по одному. В процесс написания анализаторов я стал активно выносить общий код из анализаторов в общую библиотеку и возникла проблема: если разные версии анализаторов загружены в студию — они не могут загрузить разные версии общей библиотеки. Самым простым решением оказалось сливать на этапе билда каждый анализатор с общей библиотекой в единый assembly. Для этого я воспользовался ILRepack, у которого есть удобный биндинг для MSBuild (`ILRepack.MSBuild.Task`). К сожалению, биндинг немного устарел, но это вроде бы пока не влияет.Стандартные зависимости анализаторов (Microsoft.CodeAnalysis.*) таскать с собой не нужно, и зависеть от них NuGet тоже не должен. Visual Studio сама выдаст нам нужные библиотеки.
Сборка при помощи Appveyor
Я привык настраивать непрерывную сборку проектов с исходным кодом при помощи Appveyor. Собирать и публиковать NuGet он тоже умеет. Но анализаторы — особая магия. В частности, в плане структуры директорий внутри пакета, там все по-особому, нужно раскладывать в папку analyzers вместо стандартной lib. Я немного помучился и пришел к решению — в csproj как эта сборки прописан вызов Nuget.exe, который мы таскаем с собой в пакете. Некрасиво, как мне кажется, но более красивого решения я не нашел.Написание юнит-тестов
Юнит-тесты для анализаторов — это супер классно и удобно. Я использовал стандартную MS обертку для юнит-тестов анализатора, любой false позитив тут же оформлял юнит-тестом. Классно! Гораздо приятнее, чем возиться с нечетким человеческим ТЗ.Переход на .netstandard
Перейти на .netstandart мне пока не удалось. Попытка с ходу оказалась неудачной, официальный template все еще генерит portable class библиотеки. Ждем обновленного template и попробуем сделать по нему. https://github.com/dotnet/roslyn/issues/18414Заключение
Буду рад пинкам по поводу моего подхода. Исходники можно посмотреть здесь.Буду также рад, если кто-то посоветует хорошие опенсорсные C# проекты, на которых проверить анализаторы, или проверит у себя на своих (может даже не опенсорсных) и зарепортит баги.
Очень хотелось бы ссылок на другие полезные анализаторы, желательно не дублирующие функционал Resharper.